Abstract
Quality inspection in smart manufacturing requires recognizing material and surface properties beyond visible geometry, while vision-only methods often struggle under imaging nuisances. We propose VitaTouch, a property-aware vision–tactile–language (VTL) model that integrates visual and tactile sensing with language prompts in a unified semantic space. With modality-specific encoders and dual Q-Formers, VitaTouch distills vision and touch into compact prefix tokens for a frozen large language model, enabling property reasoning and natural-language attribute description. We also build VitaSet, a VTL dataset with 186 objects, 52k multimodal images, and 5.1k instruction–answer pairs. VitaTouch achieves state-of-the-art performance on the public TVL benchmark, reaches 88.89% hardness accuracy, 75.13% roughness accuracy, and 54.81% descriptor recall on VitaSet, and maintains strong few-shot defect recognition with LoRA adaptation.
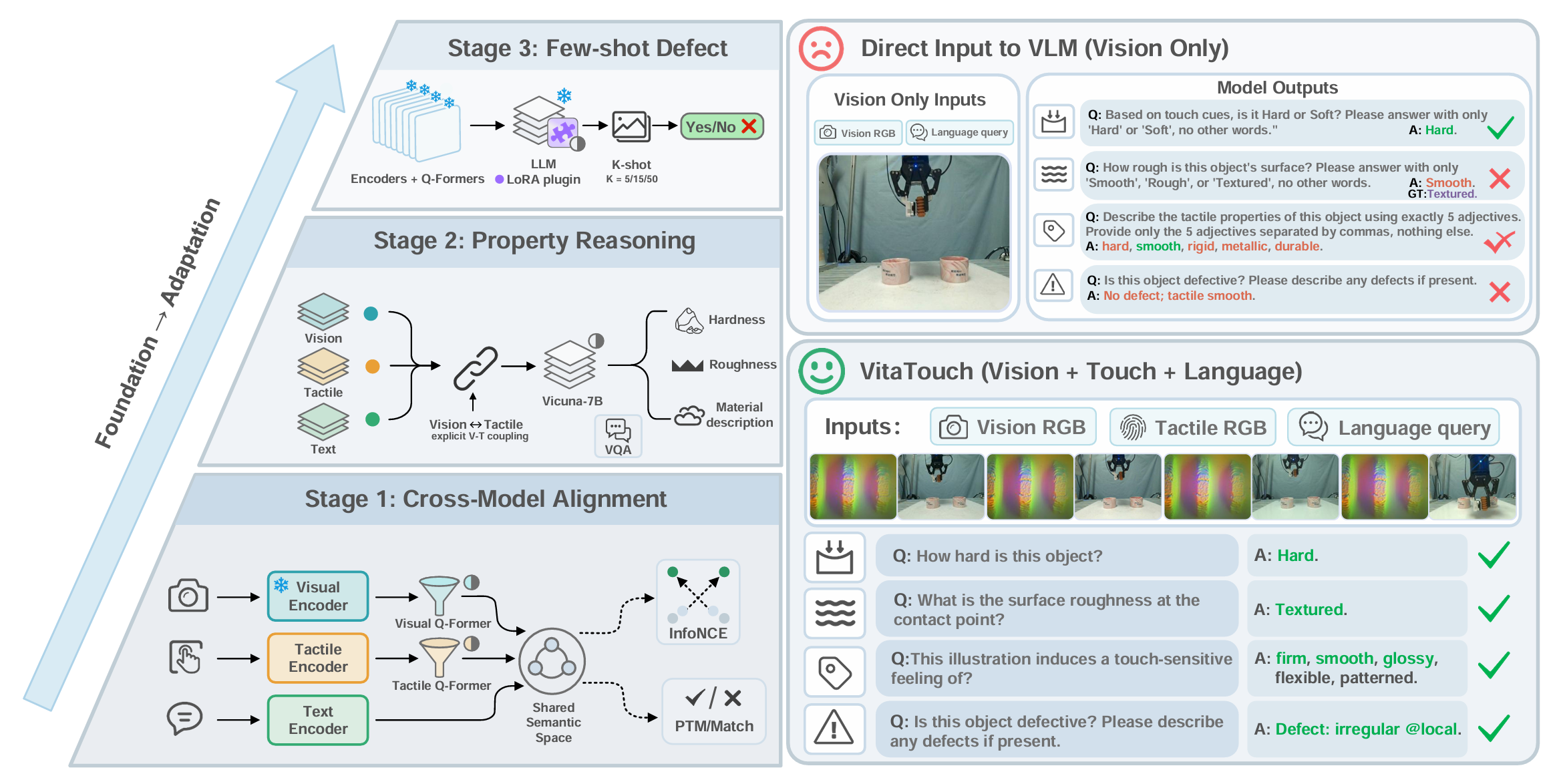
Overview of the dual-branch VitaTouch architecture and the progressive three-stage training pipeline.
VitaSet
VitaSet is a vision–tactile–language dataset for industrial quality inspection, integrating a self-collected GelSight robotic manipulation set and the GelSight-only subset of AnyTouch. It contains 186 objects, 30,553 RGB images, 21,510 GelSight tactile images (52,063 total), and 5,145 instruction–answer QA pairs under a unified annotation schema.

Method
Three-stage training
- Stage 1: Cross-modal alignment to establish a shared semantic interface across vision, touch, and language.
- Stage 2: Property-reasoning foundation learning with dual Q-Formers that distill vision–tactile prefix tokens and prepend them to a frozen Vicuna-7B decoder.
- Stage 3: Parameter-efficient few-shot defect recognition using LoRA while freezing the backbone.
Results
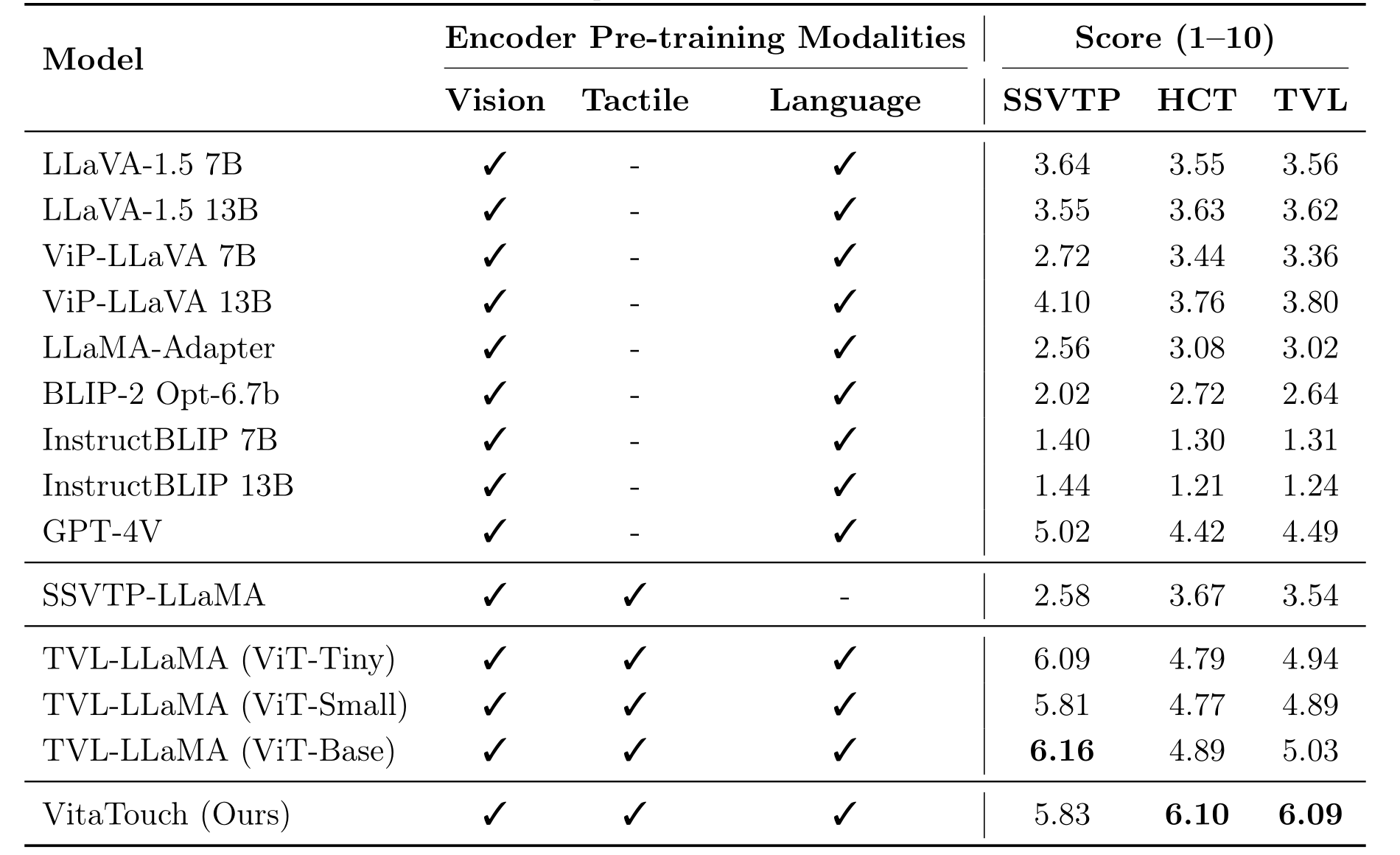
TVL Benchmark
Table 1: Comparison on the TVL benchmark. VitaTouch achieves the best performance on HCT and TVL, and remains competitive on SSVTP.
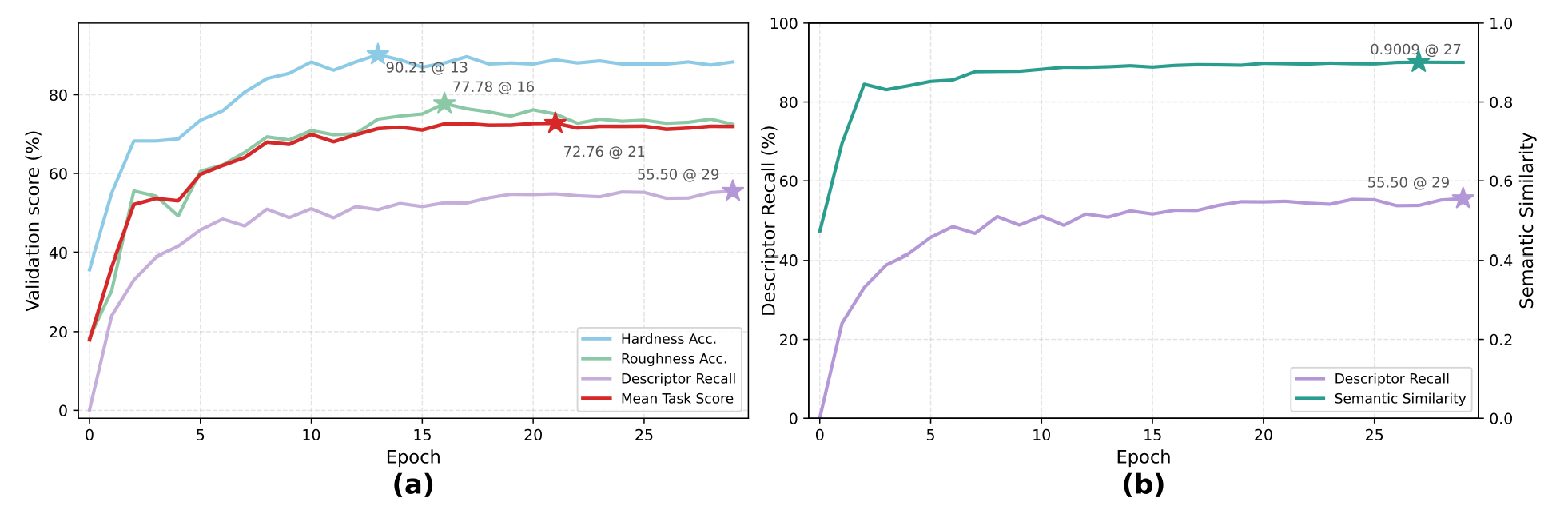
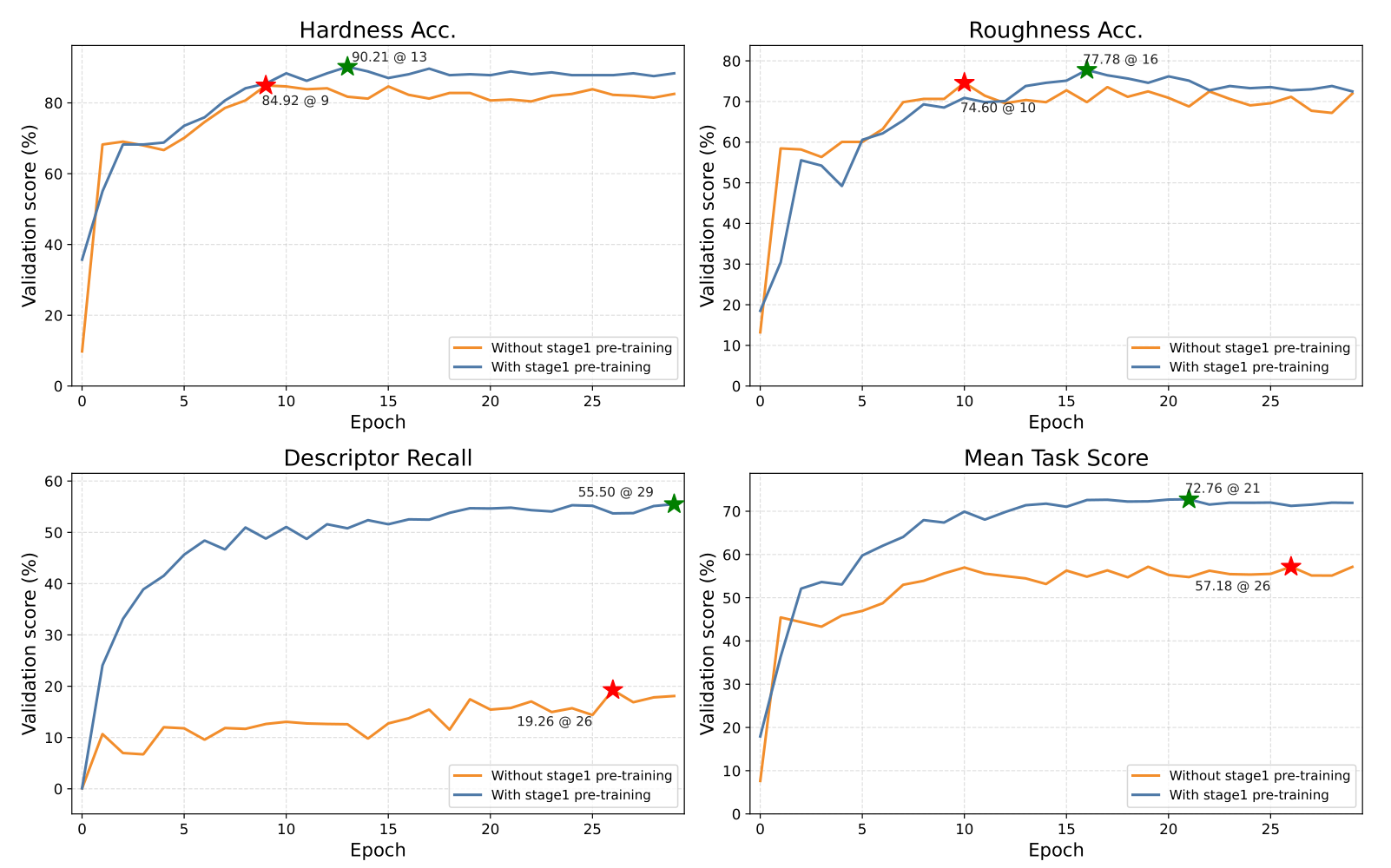
VitaSet Validation Performance
Figure 4: VitaSet validation performance of VitaTouch across training epochs. (a) Multi-task validation trends for hardness accuracy, roughness accuracy, descriptor recall, and mean task score. (b) Comparison of strict exact-match descriptor recall and semantic similarity for the material descriptor task. Stars mark the best epoch for each metric.
Ablation on VitaSet
Table 2: Comparison of the full VitaTouch model, a no-Stage-1 variant, and unimodal settings on VitaSet across tasks.
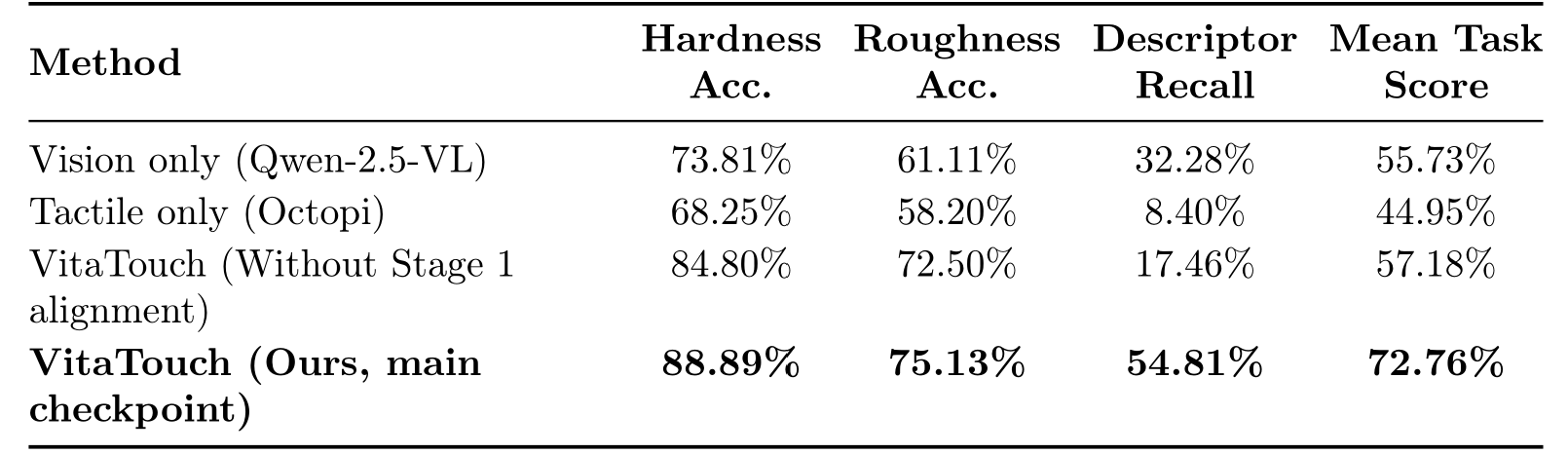
Figure 5: Ablation results on the VitaSet dataset across tasks. Each variant removes one key stage from the full model, demonstrating the necessity of explicit alignment and multimodal fusion for robust multi-task property learning.
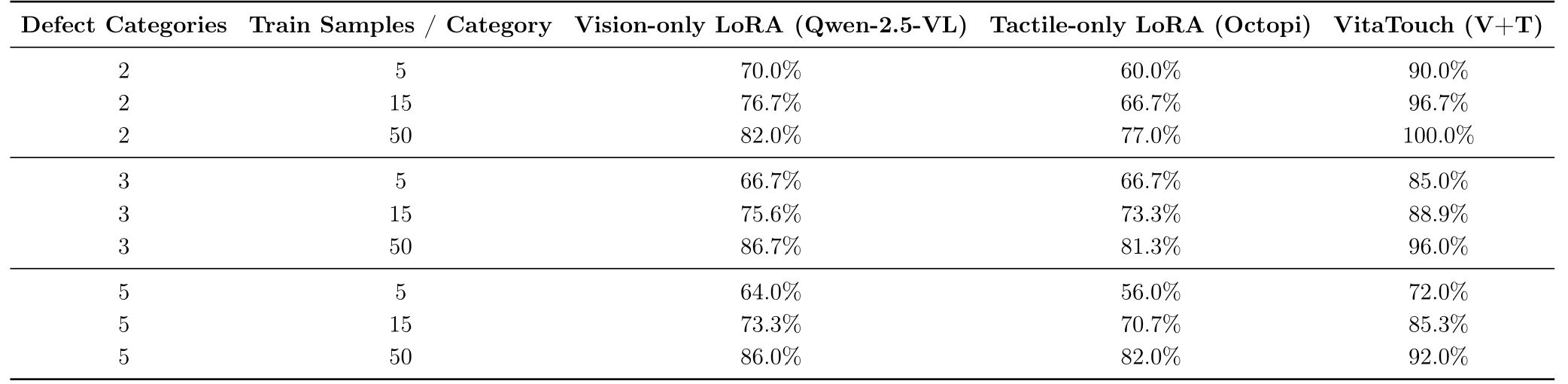
Few-shot Defect Adaptation
Table 3: LoRA-based defect adaptation results under different numbers of defect categories and labeled training samples per category. Three settings are compared: vision-only, tactile-only, and the full VitaTouch model with fused vision–tactile inputs.
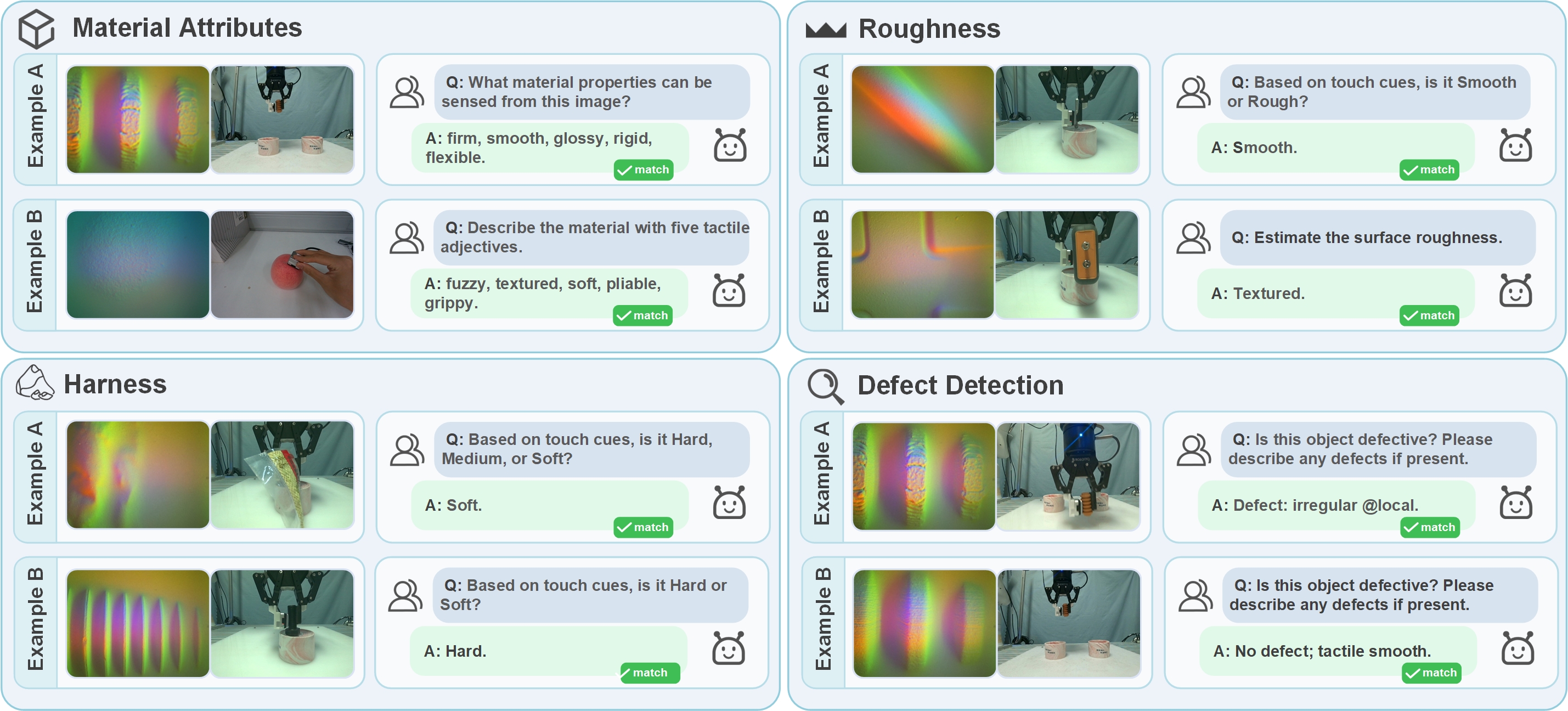
Qualitative Outputs
Figure 6: Qualitative inspection-style outputs of VitaTouch. Representative examples are shown for material descriptor prediction, hardness classification, roughness classification, and defect decision with brief descriptions.
Robotic Sorting Demonstration
Figure 7: Proof-of-concept robotic sorting demonstration. The robot performs pre-grasp, acquires tactile RGB observations during grasp, predicts defect status using the Stage 3 model, and sorts the object into the defect (left) or normal (right) bin accordingly.

Robotic Sorting Demo
We provide videos of the proof-of-concept closed-loop sorting system. The robot acquires aligned vision and tactile observations during grasp, predicts defect status using the Stage-3 model, and places objects into the left (defect) or right (normal) bin.
Defect → Left Bin
Normal → Right Bin
Citation
If you find our work useful, please consider citing:
@article{zong_vitatouch_2025,
title = {VitaTouch: Property-Aware Vision–Tactile–Language Model for Robotic Quality Inspection in Manufacturing},
author = {Zong, Junyi and Jia, Qingxuan and Shi, Meixian and Li, Tong and Li, Jiayuan and Lv, Zihang and Chen, Gang and Deng, Fang},
year = {2025}
}